|
Getting your Trinity Audio player ready...
|
Since childhood, making computers talk has been a fantasy for me. I used to think I need magical powers to make it happen. But as I grew, I learned it was possible with some coding. The system is called a “text-to-speech synthesizer.”
Introduction To Text-to-Speech
Text-to-speech (TTS) synthesizer is an assistive technology. That can read text aloud and is sometimes called “read aloud” technology. On clicking the button, the TTS synthesizer can take words on a computer or other digital device and convert them to audio.
Approaches to Developing TTS Synthesizers:
I built this system using 2 approaches:
- Using a python library
- Using a deep learning model. (This approach requires a basic knowledge of deep learning)
Approach 1: Using Python Library
In Python, there is a library called “gtts.” which converts input text into speech using Google’s Text-to-Speech API. It just requires a few lines of code to implement the system.
CODE:
from gtts import gTTS
from IPython.display import Audio
# for custom input
# text = input("Enter Text: ")
text = "Hello All, I feel so happy to be able to talk"
obj = gTTS(text, lang='en')
obj.save("audio.mp3")
Audio("audio.mp3", autoplay=False)
NOTE: Make sure you have gtts module installed in your system.
OUTPUT:
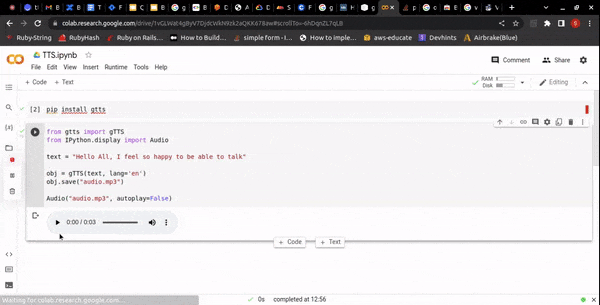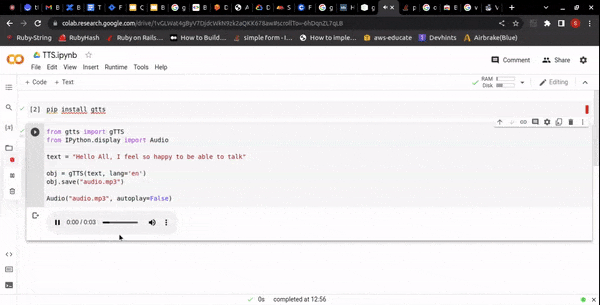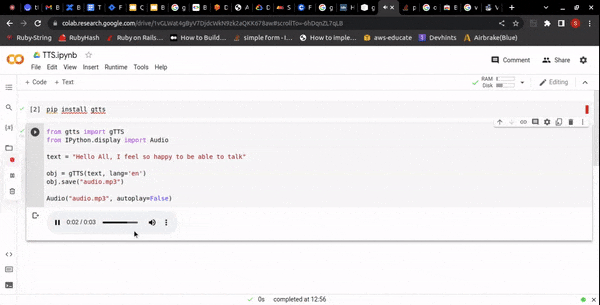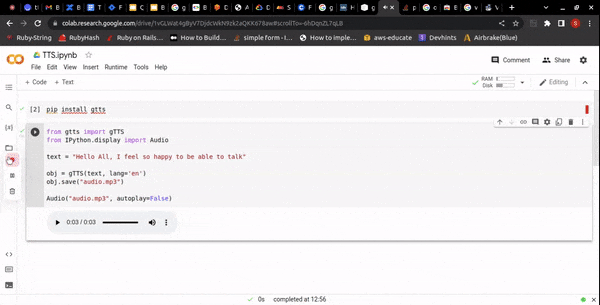
DEMO LINK:
This library can be used to generate audio in other languages. such as French, German, Hindi, etc., as well. More about this library can be found at:
Approach 2: Using a Deep Learning Model
While using that python library, you would have noticed that the generated audio sounds very robotic. To increase the accuracy of the audio and make it sound more natural, we use the concept of deep learning. But before that, we need to know what deep learning is all about.
Deep learning is an advanced concept where we write an algorithm and train it with real data such that it can act like a human brain. To implement the deep learning concept, we first need to build a model(comprised of data and a procedure on how to use the data to make predictions on new data), train it and use it in real-time applications.
Before I started building my TTS synthesizer, I did a literature survey on various deep learning models and drew the following conclusions:

From the literature survey, it is clear that the Wavenet model has the highest mean opinion score among the other models, and it is also much easier to implement. WaveNet generates more natural-sounding audio compared to other models. More about the implementation of Wavenet is at: https://www.deepmind.com/blog/wavenet-a-generative-model-for-raw-audio
Conclusion
The TTS synthesizer can be very helpful for users who struggle with reading. It can also help users with writing, editing, and even focusing. Some people stammer while speaking or struggle to pronounce some words and join speech therapy sessions. To aid their therapy, researchers are developing a human-like text-to-speech synthesizer that can generate audio from the text given. Users can feed the synthesizer a text, and it will generate audio from it that can be downloaded and heard repeatedly to improve speech. Hence, the synthesizer is mainly helpful for developing speech skills.
References
- https://arxiv.org/abs/1609.03499
- https://arxiv.org/abs/2006.03575
- https://openreview.net/pdf?id=SkxKPDv5xl
Thanks for reading!!
To learn more about Engineering topics visit – https://engineering.rently.com/
Get to know about Rently at https://use.rently.com/

Currently exploring the Tech World…