|
Getting your Trinity Audio player ready...
|

The value of incorporating White Box Testing into Manual Testing
White Box testing enhances the visibility of impacted modules for testers, enabling the identification of affected modules for code changes or issue fixes. By including these areas in manual testing, we can uncover additional bugs.
We are not validating the developer’s unit testing!
Testers are not validating the code; instead, they gain insights into the code’s capabilities and limitations. By manually executing negative scenarios based on the knowledge acquired through white box testing, bugs can be discovered.
Let’s be too Smart:
Let’s say, Quality Engineer(QE) has raised a bug and the developer has provided a new fix or a new feature has been submitted for testing. Through manual testing, our focus is primarily on retesting the issue fix/New feature and ensuring the completion of our testing process. However, during the code changes, developers may introduce irrelevant code changes. To address this, we can examine the pull request to identify any irrelevant code fixes that are unrelated to the feature being resolved.
Approaching:
In this section, we will explore several examples illustrating how to approach White Box Testing from a Quality Engineering (QE) standpoint.
Example 1:
A variable name was changed – the old variable should not be used anywhere and the new variable should be used exclusively.
Point of View (POV): An issue fix has been provided for your retesting.
Check the pull request,
Code before the issue fix:
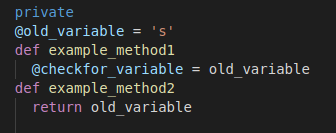
Our Observations,
- old_variable is set to ‘s’
- Under example_method1, checkfor_variable is set to old_variable
- Under example_method2 , old_variable is returned
Code after the issue fix:
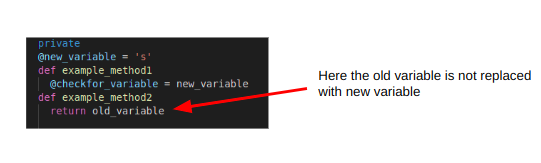
Our Observations,
- new_variable is set to ‘s’
- Under example_method1 checkfor_variable is set to new_variable
- Under example_method2, old_variable is returned.
Now, let’s address the problem at hand. A variable name has been altered, and it is crucial to ensure that the old variable is no longer employed anywhere, while the new variable is utilised in its place.
Our Learnings,
Yay! We have done Data flow coverage testing. We have meticulously examined the points where values are assigned to variables and the points where these values are utilised. By focusing on both of these aspects, we have tested the data flow.
Example 2:
There is a possibility of encountering issues within a specific flow, and these issues could potentially impact hidden flows as well.
Consider you are getting an Airbrake due to failures in a delayed job/Sidekiq job,
A delayed job failed due to bad data – looks so simple right?
⚠Warning⚠
By eliminating the erroneous data from the database(DB), we may simply bypass this issue. However, we need to consider the following questions,
- How the bad data was created?
- Will this bad data affect any other functionality?
Simple white-box testing can answer our questions. Backtrack the code and find how the bad data was created. Additionally, we should ensure that all statements utilising this data are covered, enabling us to identify any potential impact on other functionalities.
Finding how bad data was created?
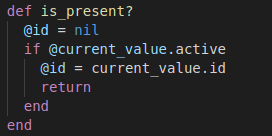
Our observations,
- The variable id is initialised with a nil value
- If the current value is active then the id is set with the id of the current value
- There is no else condition.
Now, let’s address the issue at hand. The problem lies in the fact that the variable ‘id’ will only be assigned a value if a specific condition is met. Otherwise, in the absence of an else condition, ‘id’ will retain a nil value.
Our Learnings,
Yay! We have done Condition coverage testing. Check for any unhanded condition statements.
Finding whether this bad data created will affect any other functionality.
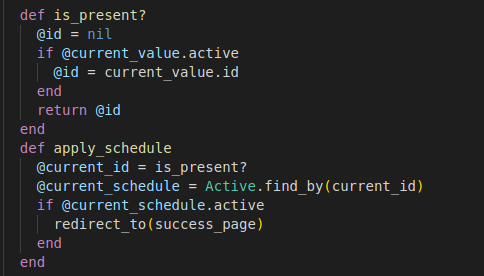
Our observations,
- apply schedule method will execute
- current_id variable will be assigned with a return value of is_present?
- is_present? will be executed → The variable id is initialized with nil value
- if the current value is active then the id is set with an id of the current value
- id value is returned (Only if the condition is executed it will have a value or it will have nil)
- current_schedule variable will be active if current_id is active
The problem arises when ‘id’ is used in this context. If a nil value is stored in ‘id’ previously, it can result in an error.
Our Learnings,
Yay! We have done Statement coverage testing. We have traversed all statements at least once, enabling us to identify the potential areas that may be impacted by an issue.
Example 3:
POV: Issue fix is provided for your retesting
Check the pull request,
Issue fix provided – specific fix, which does not cover all the impacts,
Fix provided for the Feature A
During white box testing, as we navigate through the decision points, we may discover Feature B that also has an impact on this feature. This allows us to uncover additional flows that may have an impact on an issue but were overlooked during the fix.
Our Learnings,
Yay! We have done Branch Coverage testing. By addressing each possible branch from every decision point, we have ensured that all reachable code functions as intended.
With simple examples, we have covered,
- Data flow coverage testing
- Condition coverage testing
- Statement coverage testing
- Branch Coverage testing
Bonus Points to pay attention:
The presence of the developer’s debugging code or logs within the code base is undesirable. Occasionally, developers may utilise temporary variables to store logs and inadvertently leave them in the production code base.
It is important to ensure that unused variables or pieces of code are not present within the code base.
Happy Testing!
To learn more about Quality Engineering topics visit – https://engineering.rently.com/quality-engineering/
Get to know about Rently at https://use.rently.com/
Very informative..
Well addressed and well explained. A quite informative blog for the current state of mine for improvisation. Thanks..
Very well explained. 👍
It will be very easy to understand for learners 👌
Interesting and informative article.
Very informative and helpful to understand about white box testing. Those explanations with examples were really helpful in understanding the content. Thanks and keep doing this….
Nice info! I have gained some knowledge about white box testing in an easy way through this blog.
Thanks, and keep doing it.