|
Getting your Trinity Audio player ready...
|
What is an ETL?
ETL stands for Extract, Transform, and Load. ETL is an automated data pipeline engineering methodology. The data acquired and prepared for use in a data mart or data warehouse. These data belongs to analytics environment. In ETL the data will be curated from different sources. Eventually it confirmed to a single data structure or format. Thus, the structured data loaded into its new environment.
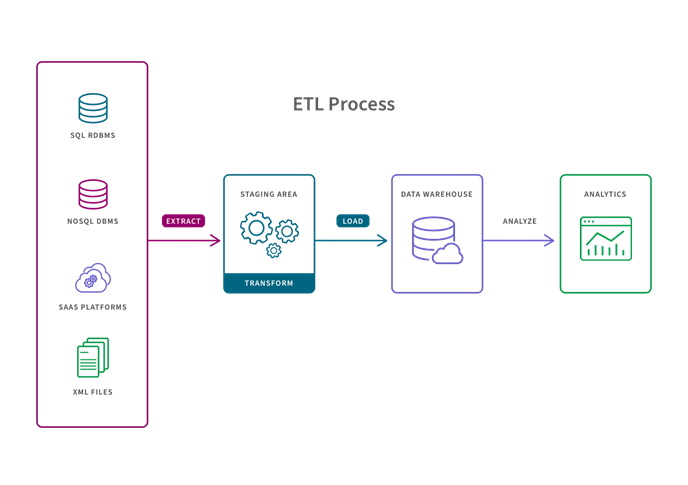
Extraction
The Extraction process reads the data from one or more sources. To extract data, need to configure access and read it into an application. however, this is an automated process. Web scraping is one of the example. In web scraping, data extracted from web pages. Basically applications like Python or R used to parse the underlying HTML code.
APIs used to connect to data and query it. The source data may be static. For example data archive. Extraction step would be a part or stage within a batch process. In other case, the data could be streaming live from many locations. Examples include data from IoT devices and weather station data. Social networking feeds also can be include during extraction process.
Transformation
The Transformation process preparing data for analysis for its destination and its intended use. This known as data wrangling. Also processing data will confirm to the requirements of both the target system and the intended use case for the curated data. Transformation can include any of the following kinds of processes. e.g. Cleaning: fixing errors for missing values. Filtering: selecting what needed. Joining disparate data sources:merging related data. Creating KPIs for machine learning from Feature engineering is one example . Formatting and data typing: making the data compatible with its destination.
Loading
Loading process takes the transformed data and loads it into its new environment. The data will be ready for visualization, exploration, further transformation, and modelling. Typical destinations include databases, data warehouses, and data marts. The key goal of data loading is to make the data
available for analytics applications. Applications include dashboards, reports, and advanced analytics such as forecasting and classification.
ETL vs ELT
What is an ELT process? ELT stands for: Extract, Load, and Transform. ELT is an
example for a specific automated data pipeline engineering method. Basically ELT is similar to ETL
in that similar stages involved. But the order in which they performed is different. For ELT
processes, data acquired. Then loaded into its destination environment. From its destination it can transformed on demand and however users wish.
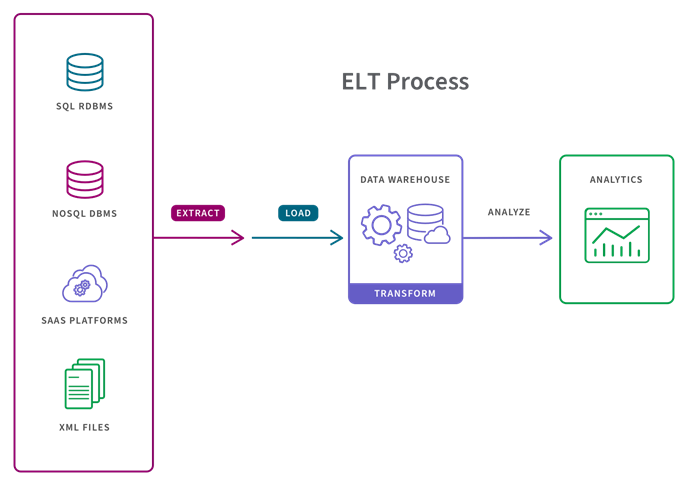
Differences between ETL and ELT:
- Transformations for ETL pipelines take place within the data pipeline, before the data reaches its destination. But transformations for ELT are separated from the data pipeline, and happen in the destination environment at will. They also differ in flexibility in how they can be used during the process.
- ETL is a fixed process meant to serve a very specific function, But ELT is flexible.
Also making data readily available for self-serve analytics. Big Data handling ability is also differs. - ETL processes handle structured, relational data, and on-premise computing
resources handle the workflow. Thus, scalability can be a problem. While ELT on the other hand,
handles any kind of data, structured and unstructured. - ETL pipelines take time and effort to modify, therefore users must wait for the development
team to implement their requested changes. But ELT provides more agility. Thus, ELT is a natural evolution of ETL.
References
https://www.coursera.org/lecture/etl-and-data-pipelines-shell-airflow-kafka/etl-fundamentals-KYsHd
Thanks for reading!!
To learn more about Engineering topics visit – https://engineering.rently.com/
Get to know about Rently at https://use.rently.com/